
Stock Classification from High Frequency Market Data
Data challenge on market data with a distribution shift. Project done during my master’s degree.
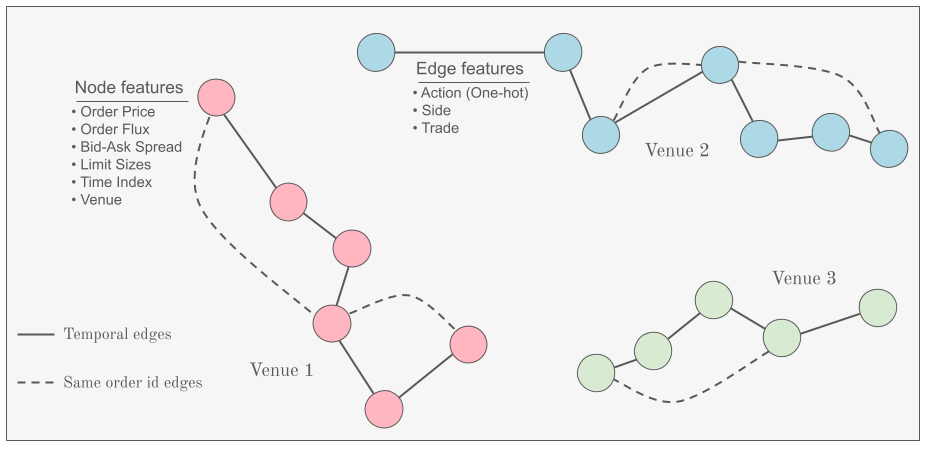
The goal of this challenge is to predict the stock corresponding to a snapshot of a given order book. Each sample is chronological sequence of 100 events of orders, posted or traded, for a given stock. To make this task challenging, a lot of the usual data features have been removed by the organizers, and some particularly revealing properties, like price or best bid and ask, have been hidden by centering the data around the first event of each sample.
- The code is available on github.
- The project report is also available on github.